示例程序¶
示例一¶
通过 http 服务向每个访问的客户端打印中文的 “你好,世界!” 和当前的时间信息。
package main
import (
"fmt"
"log"
"net/http"
"time"
)
func main() {
fmt.Println("Please visit http://127.0.0.1:12345/")
http.HandleFunc("/", func(w http.ResponseWriter, req *http.Request) {
s := fmt.Sprintf("你好, 世界! -- Time: %s", time.Now().String())
fmt.Fprintf(w, "%v\n", s)
log.Printf("%v\n", s)
})
if err := http.ListenAndServe(":12345", nil); err != nil {
log.Fatal("ListenAndServe: ", err)
}
}
通过 Go 语言标准库自带的 net/http 包构造了一个独立运行的 http 服务。其中 http.HandleFunc("/", ...) 针对 / 根路径请求注册了响应处理函数。在响应处理函数中,我们依然使用 fmt.Fprintf 格式化输出函数实现了通过 http 协议向请求的客户端打印格式化的字符串,同时通过标准库的日志包在服务器端也打印相关字符串。最后通过 http.ListenAndServe 函数调用来启动 http 服务
示例二¶
Google 在 http://chart.apis.google.com 上提供了一个将表单数据自动转换为图表的服务。不过,该服务很难交互, 因为你需要将数据作为查询放到 URL 中。此程序为一种数据格式提供了更好的的接口: 给定一小段文本,它将调用图表服务器来生成二维码(QR 码),这是一种编码文本的点格矩阵。 该图像可被你的手机摄像头捕获,并解释为一个字符串,比如 URL, 这样就免去了你在狭小的手机键盘上键入 URL 的麻烦。
package main
import (
"flag"
"html/template"
"log"
"net/http"
)
var addr = flag.String("addr", ":1718", "http service address") // Q=17, R=18
var templ = template.Must(template.New("qr").Parse(templateStr))
func main() {
flag.Parse()
http.Handle("/", http.HandlerFunc(QR))
err := http.ListenAndServe(*addr, nil)
if err != nil {
log.Fatal("ListenAndServe:", err)
}
}
func QR(w http.ResponseWriter, req *http.Request) {
templ.Execute(w, req.FormValue("s"))
}
const templateStr = `
<html>
<head>
<title>QR Link Generator</title>
</head>
<body>
{{if .}}
<img src="http://chart.apis.google.com/chart?chs=300x300&cht=qr&choe=UTF-8&chl={{.}}" />
<br>
{{.}}
<br>
<br>
{{end}}
<form action="/" name=f method="GET"><input maxLength=1024 size=70
name=s value="" title="Text to QR Encode"><input type=submit
value="Show QR" name=qr>
</form>
</body>
</html>
`
我们通过一个标志为服务器设置了默认端口。 模板变量 templ 正式有趣的地方。它构建的 HTML 模版将会被服务器执行并显示在页面中。 稍后我们将详细讨论。
main 函数解析了参数标志并使用我们讨论过的机制将 QR 函数绑定到服务器的根路径。然后调用 http.ListenAndServe 启动服务器;它将在服务器运行时处于阻塞状态。
QR 仅接受包含表单数据的请求,并为表单值 s 中的数据执行模板。
模板包 html/template 非常强大;该程序只是浅尝辄止。 本质上,它通过在运行时将数据项中提取的元素(在这里是表单值)传给 templ.Execute 执行因而重写了 HTML 文本。 在模板文本(templateStr)中,双大括号界定的文本表示模板的动作。 从 {{if .}} 到 {{end}} 的代码段仅在当前数据项(这里是点 .)的值非空时才会执行。 也就是说,当字符串为空时,此部分模板段会被忽略。
其中两段 {{.}} 表示要将数据显示在模板中 (即将查询字符串显示在 Web 页面上)。HTML 模板包将自动对文本进行转义, 因此文本的显示是安全的。
余下的模板字符串只是页面加载时将要显示的 HTML。
示例三 输入输出示例¶
// greeting.go
package main
import (
"fmt"
"strings"
)
func main() {
fmt.Println("Please enter your name.")
var name string
fmt.Scanln(&name)
fmt.Printf("Hi, %s! I'm Go!", name)
name = strings.TrimSpace(name)
}
示例四 理解 new 和 make 操作¶
package main
import (
"fmt"
"unsafe"
)
func main() {
one := make([]int, 4)
two := new([]int)
fmt.Printf("%T %T\n", one, two)
fmt.Printf("%d %d %d\n", unsafe.Sizeof(one), unsafe.Sizeof(two), unsafe.Sizeof(*two))
}
// 输出如下:
// []int *[]int
// 12 4 12
在 one 中 addr、len、capacity 各4字节,addr是underlying array的地址。
示例五 函数多返回值¶
package main
import "fmt"
//返回 A+B 和 A*B
func SumAndProduct(A, B int) (int, int) {
return A+B, A*B
}
func main() {
x := 3
y := 4
xPLUSy, xTIMESy := SumAndProduct(x, y)
fmt.Printf("%d + %d = %d\n", x, y, xPLUSy)
fmt.Printf("%d * %d = %d\n", x, y, xTIMESy)
}
示例六 函数传值不会改变外部变量值¶
package main
import "fmt"
//简单的一个函数,实现了参数+1的操作
func add1(a int) int {
a = a+1 // 我们改变了a的值
return a //返回一个新值
}
func main() {
x := 3
fmt.Println("x = ", x) // 应该输出 "x = 3"
x1 := add1(x) //调用add1(x)
fmt.Println("x+1 = ", x1) // 应该输出"x+1 = 4"
fmt.Println("x = ", x) // 应该输出"x = 3"
}
示例七 函数传指针会改变外部变量值¶
package main
import "fmt"
//简单的一个函数,实现了参数+1的操作
func add1(a *int) int { // 请注意,
*a = *a+1 // 修改了a的值
return *a // 返回新值
}
func main() {
x := 3
fmt.Println("x = ", x) // 应该输出 "x = 3"
x1 := add1(&x) // 调用 add1(&x) 传x的地址
fmt.Println("x+1 = ", x1) // 应该输出 "x+1 = 4"
fmt.Println("x = ", x) // 应该输出 "x = 4"
}
示例八 defer 语句¶
在defer后指定的函数会在函数退出前调用。
func ReadWrite() bool {
file.Open("file")
defer file.Close()
if failureX {
return false
}
if failureY {
return false
}
return true
}
如果有很多调用defer,那么defer是采用后进先出模式,所以如下代码会输出4 3 2 1 0
for i := 0; i < 5; i++ {
defer fmt.Printf("%d ", i)
}
示例九 函数作为值、类型¶
package main
import "fmt"
type testInt func(int) bool // 声明了一个函数类型
func isOdd(integer int) bool {
if integer%2 == 0 {
return false
}
return true
}
func isEven(integer int) bool {
if integer%2 == 0 {
return true
}
return false
}
// 声明的函数类型在这个地方当做了一个参数
func filter(slice []int, f testInt) []int {
var result []int
for _, value := range slice {
if f(value) {
result = append(result, value)
}
}
return result
}
func main(){
slice := []int {1, 2, 3, 4, 5, 7}
fmt.Println("slice = ", slice)
odd := filter(slice, isOdd) // 函数当做值来传递了
fmt.Println("Odd elements of slice are: ", odd)
even := filter(slice, isEven) // 函数当做值来传递了
fmt.Println("Even elements of slice are: ", even)
}
示例十 使用 panic 和 recover¶
var user = os.Getenv("USER")
func init() {
if user == "" {
panic("no value for $USER")
}
}
下面这个函数检查作为其参数的函数在执行时是否会产生panic:
func throwsPanic(f func()) (b bool) {
defer func() {
if x := recover(); x != nil {
b = true
}
}()
f() //执行函数f,如果f中出现了panic,那么就可以恢复回来
return
}
示例十一 struct 的用法¶
type person struct {
name string
age int
}
var P person // P现在就是person类型的变量了
P.name = "Astaxie" // 赋值"Astaxie"给P的name属性.
P.age = 25 // 赋值"25"给变量P的age属性
fmt.Printf("The person's name is %s", P.name) // 访问P的name属性.
除了上面这种P的声明使用之外,还有另外几种声明使用方式:
- 1.按照顺序提供初始化值
P := person{"Tom", 25}
- 2.通过
field:value的方式初始化,这样可以任意顺序
P := person{age:24, name:"Tom"}
- 3.当然也可以通过
new函数分配一个指针,此处P的类型为*person
P := new(person)
下面我们看一个完整的使用struct的例子:
package main
import "fmt"
// 声明一个新的类型
type person struct {
name string
age int
}
// 比较两个人的年龄,返回年龄大的那个人,并且返回年龄差
// struct也是传值的
func Older(p1, p2 person) (person, int) {
if p1.age>p2.age { // 比较p1和p2这两个人的年龄
return p1, p1.age-p2.age
}
return p2, p2.age-p1.age
}
func main() {
var tom person
// 赋值初始化
tom.name, tom.age = "Tom", 18
// 两个字段都写清楚的初始化
bob := person{age:25, name:"Bob"}
// 按照struct定义顺序初始化值
paul := person{"Paul", 43}
tb_Older, tb_diff := Older(tom, bob)
tp_Older, tp_diff := Older(tom, paul)
bp_Older, bp_diff := Older(bob, paul)
fmt.Printf("Of %s and %s, %s is older by %d years\n",
tom.name, bob.name, tb_Older.name, tb_diff)
fmt.Printf("Of %s and %s, %s is older by %d years\n",
tom.name, paul.name, tp_Older.name, tp_diff)
fmt.Printf("Of %s and %s, %s is older by %d years\n",
bob.name, paul.name, bp_Older.name, bp_diff)
}
示例十二 switch 测试¶
element.(type)语法不能在switch外的任何逻辑里面使用,如果要在switch外面判断一个类型就使用comma-ok。
package main
import (
"fmt"
"strconv"
)
type Element interface{}
type List [] Element
type Person struct {
name string
age int
}
//打印
func (p Person) String() string {
return "(name: " + p.name + " - age: "+strconv.Itoa(p.age)+ " years)"
}
func main() {
list := make(List, 3)
list[0] = 1 //an int
list[1] = "Hello" //a string
list[2] = Person{"Dennis", 70}
for index, element := range list{
switch value := element.(type) {
case int:
fmt.Printf("list[%d] is an int and its value is %d\n", index, value)
case string:
fmt.Printf("list[%d] is a string and its value is %s\n", index, value)
case Person:
fmt.Printf("list[%d] is a Person and its value is %s\n", index, value)
default:
fmt.Println("list[%d] is of a different type", index)
}
}
}
示例十三 无缓冲 channel¶
无缓冲 channel 是阻塞的。
package main
import "fmt"
func sum(a []int, c chan int) {
total := 0
for _, v := range a {
total += v
}
c <- total // send total to c
}
func main() {
a := []int{7, 2, 8, -9, 4, 0}
c := make(chan int)
go sum(a[:len(a)/2], c)
go sum(a[len(a)/2:], c)
x, y := <-c, <-c // receive from c
fmt.Println(x, y, x + y)
}
示例十四 有缓存的 channel¶
有缓存的 channel 是非阻塞的。
package main
import "fmt"
func main() {
c := make(chan int, 2)//修改2为1就报错,修改2为3可以正常运行
c <- 1
c <- 2
fmt.Println(<-c)
fmt.Println(<-c)
}
//修改为1报如下的错误:
//fatal error: all goroutines are asleep - deadlock!
示例十五 net/http 包建立一个 Web 服务器¶
package main
import (
"fmt"
"net/http"
"strings"
"log"
)
func sayhelloName(w http.ResponseWriter, r *http.Request) {
r.ParseForm() //解析参数,默认是不会解析的
fmt.Println(r.Form) //这些信息是输出到服务器端的打印信息
fmt.Println("path", r.URL.Path)
fmt.Println("scheme", r.URL.Scheme)
fmt.Println(r.Form["url_long"])
for k, v := range r.Form {
fmt.Println("key:", k)
fmt.Println("val:", strings.Join(v, ""))
}
fmt.Fprintf(w, "Hello winnerwinter!") //这个写入到w的是输出到客户端的
}
func main() {
http.HandleFunc("/", sayhelloName) //设置访问的路由
err := http.ListenAndServe(":9090", nil) //设置监听的端口
if err != nil {
log.Fatal("ListenAndServe: ", err)
}
}
示例十六 数学意义不严格的函数式编程¶
闭包函数以引用的方式访问外部变量。
package main
import (
"fmt"
)
func adder() func(int) int {
sum := 0
return func(v int) int {
sum += v
return sum
}
}
func main() {
a := adder()
for i := 0; i < 10; i++ {
fmt.Println(a(i))
}
}
示例十七 基于管道的随机数生成器¶
随机数的一个特点是不好预测。如果一个随机数的输出是可以简单预测的,那么一般会称为伪随机数。
func main() {
for i := range random(100) {
fmt.Println(i)
}
}
func random(n int) <-chan int {
c := make(chan int)
go func() {
defer close(c)
for i := 0; i < n; i++ {
select {
case c <- 0:
case c <- 1:
}
}
}()
return c
}
基于select语言特性构造的随机数生成器。
示例十八 空数组用于管道的同步操作¶
c1 := make(chan [0]int)
go func() {
fmt.Println("c1")
c1 <- [0]int{}
}()
<-c1
在这里,我们并不关心管道中传输数据的真实类型,其中管道接收和发送操作只是用于消息的同步。对于这种场景,我们用空数组来作为管道类型可以减少管道元素赋值时的开销。当然一般更倾向于用无类型的匿名结构体代替:
c2 := make(chan struct{})
go func() {
fmt.Println("c2")
c2 <- struct{}{} // struct{}部分是类型, {}表示对应的结构体值
}()
<-c2
示例十九 可变参数其实是切片类型¶
// 多个参数和多个返回值
func Swap(a, b int) (int, int) {
return b, a
}
// 可变数量的参数
// more 对应 []int 切片类型
func Sum(a int, more ...int) int {
for _, v := range more {
a += v
}
return a
}
示例二十 空接口类型变参是否被解包会导致不同的结果¶
func main() {
var a = []interface{}{123, "abc"}
Print(a...) // 123 abc
Print(a) // [123 abc]
}
func Print(a ...interface{}) {
fmt.Println(a...)
}
第一个Print调用时传入的参数是a...,等价于直接调用Print(123, "abc")。第二个Print调用传入的是未解包的a,等价于直接调用Print([]interface{}{123, "abc"})。
示例二十一 闭包可能导致隐含问题¶
func main() {
for i := 0; i < 3; i++ {
defer func(){ println(i) } ()
}
}
// Output:
// 3
// 3
// 3
因为是闭包,在for迭代语句中,每个defer语句延迟执行的函数引用的都是同一个i迭代变量,在循环结束后这个变量的值为3,因此最终输出的都是3。
修复的思路是在每轮迭代中为每个defer函数生成独有的变量。可以用下面两种方式:
func main() {
for i := 0; i < 3; i++ {
i := i // 定义一个循环体内局部变量i
defer func(){ println(i) } ()
}
}
func main() {
for i := 0; i < 3; i++ {
// 通过函数传入i
// defer 语句会马上对调用参数求值
defer func(i int){ println(i) } (i)
}
}
第一种方法是在循环体内部再定义一个局部变量,这样每次迭代defer语句的闭包函数捕获的都是不同的变量,这些变量的值对应迭代时的值。
第二种方式是将迭代变量通过闭包函数的参数传入,defer语句会马上对调用参数求值。两种方式都是可以工作的。
示例二十二 生产者-消费者模型¶
// 生产者: 生成 factor 整数倍的序列
func Producer(factor int, out chan<- int) {
for i := 0; ; i++ {
out <- i*factor
}
}
// 消费者
func Consumer(in <-chan int) {
for v := range in {
fmt.Println(v)
}
}
func main() {
ch := make(chan int, 64) // 成果队列
go Producer(3, ch) // 生成 3 的倍数的序列
go Producer(5, ch) // 生成 5 的倍数的序列
go Consumer(ch) // 消费 生成的队列
// Ctrl+C 退出
sig := make(chan os.Signal, 1)
signal.Notify(sig, syscall.SIGINT, syscall.SIGTERM)
fmt.Printf("quit (%v)\n", <-sig)
}
示例二十五 发布订阅模型¶
发布订阅(publish-and-subscribe)模型通常被简写为pub/sub模型。在这个模型中,消息生产者成为发布者(publisher),而消息消费者则成为订阅者(subscriber),生产者和消费者是M:N的关系。在传统生产者和消费者模型中,是将消息发送到一个队列中,而发布订阅模型则是将消息发布给一个主题。
为此,我们构建了一个名为pubsub的发布订阅模型支持包:
// Package pubsub implements a simple multi-topic pub-sub library.
package pubsub
import (
"sync"
"time"
)
type (
subscriber chan interface{} // 订阅者为一个管道
topicFunc func(v interface{}) bool // 主题为一个过滤器
)
// 发布者对象
type Publisher struct {
m sync.RWMutex // 读写锁
buffer int // 订阅队列的缓存大小
timeout time.Duration // 发布超时时间
subscribers map[subscriber]topicFunc // 订阅者信息
}
// 构建一个发布者对象, 可以设置发布超时时间和缓存队列的长度
func NewPublisher(publishTimeout time.Duration, buffer int) *Publisher {
return &Publisher{
buffer: buffer,
timeout: publishTimeout,
subscribers: make(map[subscriber]topicFunc),
}
}
// 添加一个新的订阅者,订阅全部主题
func (p *Publisher) Subscribe() chan interface{} {
return p.SubscribeTopic(nil)
}
// 添加一个新的订阅者,订阅过滤器筛选后的主题
func (p *Publisher) SubscribeTopic(topic topicFunc) chan interface{} {
ch := make(chan interface{}, p.buffer)
p.m.Lock()
p.subscribers[ch] = topic
p.m.Unlock()
return ch
}
// 退出订阅
func (p *Publisher) Evict(sub chan interface{}) {
p.m.Lock()
defer p.m.Unlock()
delete(p.subscribers, sub)
close(sub)
}
// 发布一个主题
func (p *Publisher) Publish(v interface{}) {
p.m.RLock()
defer p.m.RUnlock()
var wg sync.WaitGroup
for sub, topic := range p.subscribers {
wg.Add(1)
go p.sendTopic(sub, topic, v, &wg)
}
wg.Wait()
}
// 关闭发布者对象,同时关闭所有的订阅者管道。
func (p *Publisher) Close() {
p.m.Lock()
defer p.m.Unlock()
for sub := range p.subscribers {
delete(p.subscribers, sub)
close(sub)
}
}
// 发送主题,可以容忍一定的超时
func (p *Publisher) sendTopic(
sub subscriber, topic topicFunc, v interface{}, wg *sync.WaitGroup,
) {
defer wg.Done()
if topic != nil && !topic(v) {
return
}
select {
case sub <- v:
case <-time.After(p.timeout):
}
}
下面的例子中,有两个订阅者分别订阅了全部主题和含有"golang"的主题:
import "path/to/pubsub"
func main() {
p := pubsub.NewPublisher(100*time.Millisecond, 10)
defer p.Close()
all := p.Subscribe()
golang := p.SubscribeTopic(func(v interface{}) bool {
if s, ok := v.(string); ok {
return strings.Contains(s, "golang")
}
return false
})
p.Publish("hello, world!")
p.Publish("hello, golang!")
go func() {
for msg := range all {
fmt.Println("all:", msg)
}
} ()
go func() {
for msg := range golang {
fmt.Println("golang:", msg)
}
} ()
// 运行一定时间后退出
time.Sleep(3 * time.Second)
}
在发布订阅模型中,每条消息都会传送给多个订阅者。发布者通常不会知道、也不关心哪一个订阅者正在接收主题消息。订阅者和发布者可以在运行时动态添加,是一种松散的耦合关系,这使得系统的复杂性可以随时间的推移而增长。在现实生活中,像天气预报之类的应用就可以应用这个并发模式。
示例二十四 使用sync.WaitGroup等待一组事件¶
func main() {
var wg sync.WaitGroup
// 开N个后台打印线程
for i := 0; i < 10; i++ {
wg.Add(1) // 增加等待事件
go func() {
fmt.Println("你好, 世界")
wg.Done() // 完成一个事件
}()
}
// 等待N个后台线程完成
wg.Wait()
}
示例二十五 切片代码示例¶
切片内存技巧¶
对于切片来说,len为0但是cap容量不为0的切片是非常有用的特性。当然,如果len和cap都为0的话,则变成一个真正的空切片,虽然它并不是一个nil值的切片。在判断一个切片是否为空时,一般通过len获取切片的长度来判断,一般很少将切片和nil值做直接的比较。
比如下面的TrimSpace函数用于删除[]byte中的空格。函数实现利用了0长切片的特性,实现高效而且简洁。
func TrimSpace(s []byte) []byte {
b := s[:0]
for _, x := range s {
if x != ' ' {
b = append(b, x)
}
}
return b
}
其实类似的根据过滤条件原地删除切片元素的算法都可以采用类似的方式处理(因为是删除操作不会出现内存不足的情形):
func Filter(s []byte, fn func(x byte) bool) []byte {
b := s[:0]
for _, x := range s {
if !fn(x) {
b = append(b, x)
}
}
return b
}
切片高效操作的要点是要降低内存分配的次数,尽量保证append操作不会超出cap的容量,降低触发内存分配的次数和每次分配内存大小。
避免切片内存泄漏¶
切片操作并不会复制底层的数据。底层的数组会被保存在内存中,直到它不再被引用。但是有时候可能会因为一个小的内存引用而导致底层整个数组处于被使用的状态,这会延迟自动内存回收器对底层数组的回收。
例如,FindPhoneNumber函数加载整个文件到内存,然后搜索第一个出现的电话号码,最后结果以切片方式返回。
func FindPhoneNumber(filename string) []byte {
b, _ := ioutil.ReadFile(filename)
return regexp.MustCompile("[0-9]+").Find(b)
}
这段代码返回的[]byte指向保存整个文件的数组。因为切片引用了整个原始数组,导致自动垃圾回收器不能及时释放底层数组的空间。一个小的需求可能导致需要长时间保存整个文件数据。这虽然这并不是传统意义上的内存泄漏,但是可能会拖慢系统的整体性能。
要修复这个问题,可以将感兴趣的数据复制到一个新的切片中(数据的传值是Go语言编程的一个哲学,虽然传值有一定的代价,但是换取的好处是切断了对原始数据的依赖):
func FindPhoneNumber(filename string) []byte {
b, _ := ioutil.ReadFile(filename)
b = regexp.MustCompile("[0-9]+").Find(b)
return append([]byte{}, b...)
}
类似的问题,在删除切片元素时可能会遇到。假设切片里存放的是指针对象,那么下面删除末尾的元素后,被删除的元素依然被切片底层数组引用,从而导致不能及时被自动垃圾回收器回收(这要依赖回收器的实现方式):
var a []*int{ ... }
a = a[:len(a)-1] // 被删除的最后一个元素依然被引用, 可能导致GC操作被阻碍
保险的方式是先将需要自动内存回收的元素设置为nil,保证自动回收器可以发现需要回收的对象,然后再进行切片的删除操作:
var a []*int{ ... }
a[len(a)-1] = nil // GC回收最后一个元素内存
a = a[:len(a)-1] // 从切片删除最后一个元素
当然,如果切片存在的周期很短的话,可以不用刻意处理这个问题。因为如果切片本身已经可以被GC回收的话,切片对应的每个元素自然也就是可以被回收的了。
切片类型强制转换¶
为了安全,当两个切片类型[]T和[]Y的底层原始切片类型不同时,Go语言是无法直接转换类型的。不过安全都是有一定代价的,有时候这种转换是有它的价值的——可以简化编码或者是提升代码的性能。比如在64位系统上,需要对一个[]float64切片进行高速排序,我们可以将它强制转为[]int整数切片,然后以整数的方式进行排序(因为float64遵循IEEE754浮点数标准特性,当浮点数有序时对应的整数也必然是有序的)。
下面的代码通过两种方法将[]float64类型的切片转换为[]int类型的切片:
// +build amd64 arm64
import "sort"
var a = []float64{4, 2, 5, 7, 2, 1, 88, 1}
func SortFloat64FastV1(a []float64) {
// 强制类型转换
var b []int = ((*[1 << 20]int)(unsafe.Pointer(&a[0])))[:len(a):cap(a)]
// 以int方式给float64排序
sort.Ints(b)
}
func SortFloat64FastV2(a []float64) {
// 通过 reflect.SliceHeader 更新切片头部信息实现转换
var c []int
aHdr := (*reflect.SliceHeader)(unsafe.Pointer(&a))
cHdr := (*reflect.SliceHeader)(unsafe.Pointer(&c))
*cHdr = *aHdr
// 以int方式给float64排序
sort.Ints(c)
}
第一种强制转换是**先将切片数据的开始地址转换为一个较大的数组的指针,然后对数组指针对应的数组重新做切片操作。**中间需要unsafe.Pointer来连接两个不同类型的指针传递。需要注意的是,Go语言实现中非0大小数组的长度不得超过2GB,因此需要针对数组元素的类型大小计算数组的最大长度范围([]uint8最大2GB,[]uint16最大1GB,以此类推,但是[]struct{}数组的长度可以超过2GB)。
第二种转换操作是**分别取到两个不同类型的切片头信息指针**,任何类型的切片头部信息底层都是对应reflect.SliceHeader结构,然后通过更新结构体方式来更新切片信息,从而实现a对应的[]float64切片到c对应的[]int类型切片的转换。
通过基准测试,我们可以发现用sort.Ints对转换后的[]int排序的性能要比用sort.Float64s排序的性能好一点。不过需要注意的是,这个方法可行的前提是**要保证[]float64中没有 NaN 和 Inf 等非规范的浮点数**(因为浮点数中NaN不可排序,正0和负0相等,但是整数中没有这类情形)。
示例二十六 素数筛¶
“素数筛”的原理如图:
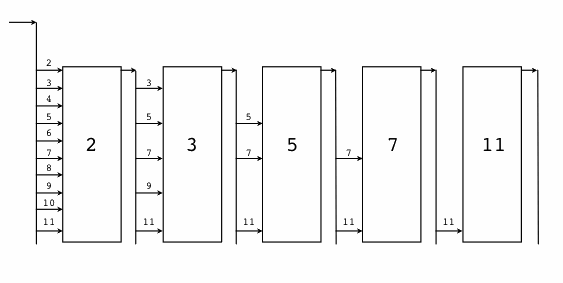
我们需要先生成最初的2, 3, 4, ...自然数序列(不包含开头的0、1):
// 返回生成自然数序列的管道: 2, 3, 4, ...
func GenerateNatural() chan int {
ch := make(chan int)
go func() {
for i := 2; ; i++ {
ch <- i
}
}()
return ch
}
GenerateNatural函数内部启动一个Goroutine生产序列,返回对应的管道。
然后是为每个素数构造一个筛子:将输入序列中是素数倍数的数提出,并返回新的序列,是一个新的管道。
// 管道过滤器: 删除能被素数整除的数
func PrimeFilter(in <-chan int, prime int) chan int {
out := make(chan int)
go func() {
for {
if i := <-in; i%prime != 0 {
out <- i
}
}
}()
return out
}
PrimeFilter函数也是内部启动一个Goroutine生产序列,返回过滤后序列对应的管道。
现在我们可以在main函数中驱动这个并发的素数筛了:
func main() {
ch := GenerateNatural() // 自然数序列: 2, 3, 4, ...
for i := 0; i < 100; i++ {
prime := <-ch // 新出现的素数
fmt.Printf("%v: %v\n", i+1, prime)
ch = PrimeFilter(ch, prime) // 基于新素数构造的过滤器
}
}
我们先是调用GenerateNatural()生成最原始的从2开始的自然数序列。然后开始一个100次迭代的循环,希望生成100个素数。在每次循环迭代开始的时候,管道中的第一个数必定是素数,我们先读取并打印这个素数。然后基于管道中剩余的数列,并以当前取出的素数为筛子过滤后面的素数。不同的素数筛子对应的管道是串联在一起的。
素数筛展示了一种优雅的并发程序结构。但是因为每个并发体处理的任务粒度太细微,程序整体的性能并不理想。对于细粒度的并发程序,CSP模型中固有的消息传递的代价太高了(多线程并发模型同样要面临线程启动的代价)。
GenerateNatural和PrimeFilter函数内部都启动了新的Goroutine,当main函数不再使用管道时后台Goroutine有泄漏的风险。我们可以通过context包来避免这个问题,下面是改进的素数筛实现:
// 返回生成自然数序列的管道: 2, 3, 4, ...
func GenerateNatural(ctx context.Context) chan int {
ch := make(chan int)
go func() {
for i := 2; ; i++ {
select {
case <- ctx.Done():
return
case ch <- i:
}
}
}()
return ch
}
// 管道过滤器: 删除能被素数整除的数
func PrimeFilter(ctx context.Context, in <-chan int, prime int) chan int {
out := make(chan int)
go func() {
for {
if i := <-in; i%prime != 0 {
select {
case <- ctx.Done():
return
case out <- i:
}
}
}
}()
return out
}
func main() {
// 通过 Context 控制后台Goroutine状态
ctx, cancel := context.WithCancel(context.Background())
ch := GenerateNatural(ctx) // 自然数序列: 2, 3, 4, ...
for i := 0; i < 100; i++ {
prime := <-ch // 新出现的素数
fmt.Printf("%v: %v\n", i+1, prime)
ch = PrimeFilter(ctx, ch, prime) // 基于新素数构造的过滤器
}
cancel()
}
当main函数完成工作前,通过调用cancel()来通知后台Goroutine退出,这样就避免了Goroutine的泄漏。